
- 製品説明
-
AIワークロードに対応したコンパクトなグラフィックスボード
GPUにNVIDIA RTX PRO 2000 Blackwellを搭載したグラフィックスボードです。ボード消費電力を70Wに抑え、補助電源なしで動作するため、小型、薄型のワークステーションでの利用に最適です。AIコンピューティングやビジュアライゼーション、ビデオ編集などのタスクを高いパフォーマンスで実行できます。
NVIDIA Blackwellアーキテクチャ採用
NVIDIA Blackwellアーキテクチャは、画期的なAI、レイトレーシング、ニューラルグラフィックステクノロジと、大幅なパフォーマンスとメモリの増加を組み合わせ、どこからでも最先端のプロフェッショナルなクリエイティブ、設計、エンジニアリングワークフローを推進します。
エンタープライズの信頼性
NVIDIA RTX PROソリューションはプロフェッショナル向けに設計されており、最高のパフォーマンスを求める人のためにデザインされています。全てのGPUは厳しいテストをパスしており、エンタープライズドライバーによって継続的に最適化されています。広範なISV認定や堅牢なIT管理ツール、エンタープライズグレードのサポートなどにより、業務利用やミッションクリティカルな用途で安心してご利用頂けます。
- AI処理ベンチマーク結果(Geekbench AIスコア)
-
Geekbench AIは、実際の機械学習タスクを使用して AI のパフォーマンスを評価する AI ベンチマークソフトです。
以下のハードウェア条件で内蔵グラフィックス、各グラフィックスボードのスコアを計測しました。
・型番 LC-9EM05
・CPU Core i7-13700E
・RAM 32GB
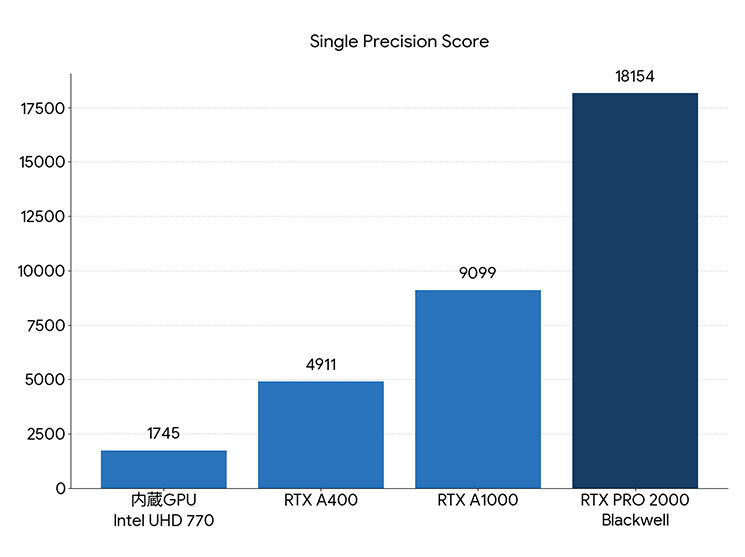
Single Precision Score (単精度):精度優先の処理向け。数値の安定性が最優先の計算、推論の実行で使われます。
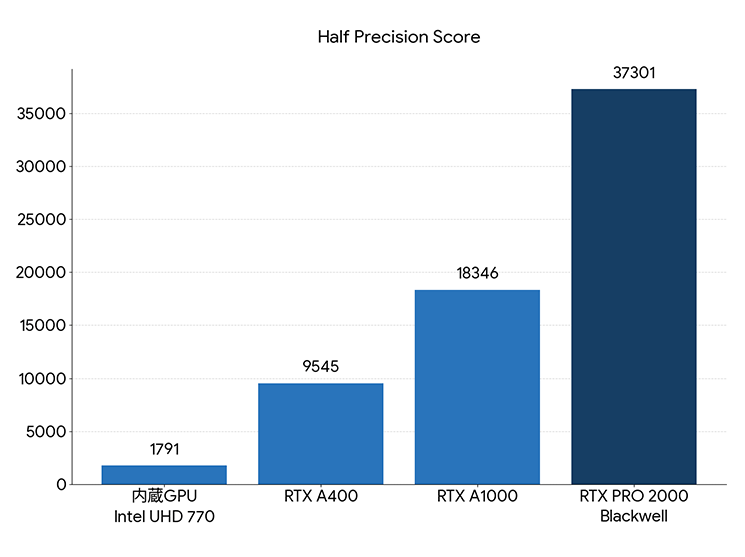
Half Precision Score (半精度):実用推論の主力。GPUでの高速推論で使われます。
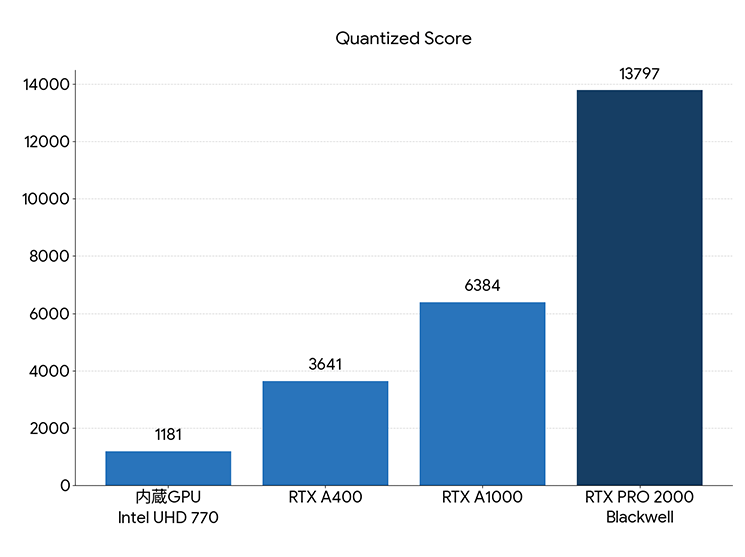
Quantized Score (量子化):軽量・省電力運用向け。ローカル推論、エッジ機器、サーバーの大量推論、LLMを少ないVRAMで動かす用途で使われます。
結果と、実際にアプリケーションを使用した際のパフォーマンスは異なる場合があります。
- 主な仕様
-
NVIDIA RTX PRO 2000 Blackwell GPUアーキテクチャ Blackwell NVIDIA CUDAコア数 4,352 NVIDIA 第5世代 Tensorコア数 136 NVIDIA 第4世代 RTコア数 34 AI TOPS ※1※2 545 単精度演算性能※1 17 RT コア性能※1 52 GPUメモリー GDDR7 16GB(ECC対応) メモリーインターフェース 128bit メモリー帯域幅 288GB/s システムインターフェース PCI Express 5.0 x8(形状はx16) ディスプレイコネクター Mini DisplayPort 2.1b×4 ビデオエンジン 第9世代NVENC×1
第6世代NVDEC×1最大消費電力 70W 電源コネクター なし サーマルソリューション アクティブ 外形寸法 約167.64(L)×68.58(H) mm(デュアルスロット) グラフィックスAPI DirectX 12、Shader Model 6.7、OpenGL 4.6、Vulkan 1.4 コンピュートAPI CUDA 12.8、OpenCL 3.0 ※1.ピークレートはGPUブーストクロックに基づきます。
※2.スパース性を考慮した実効FP4 TOPS